
The various categories of guidelines are described below.
These guidelines support SDMx design projects which follow the pattern shown in the diagram below.
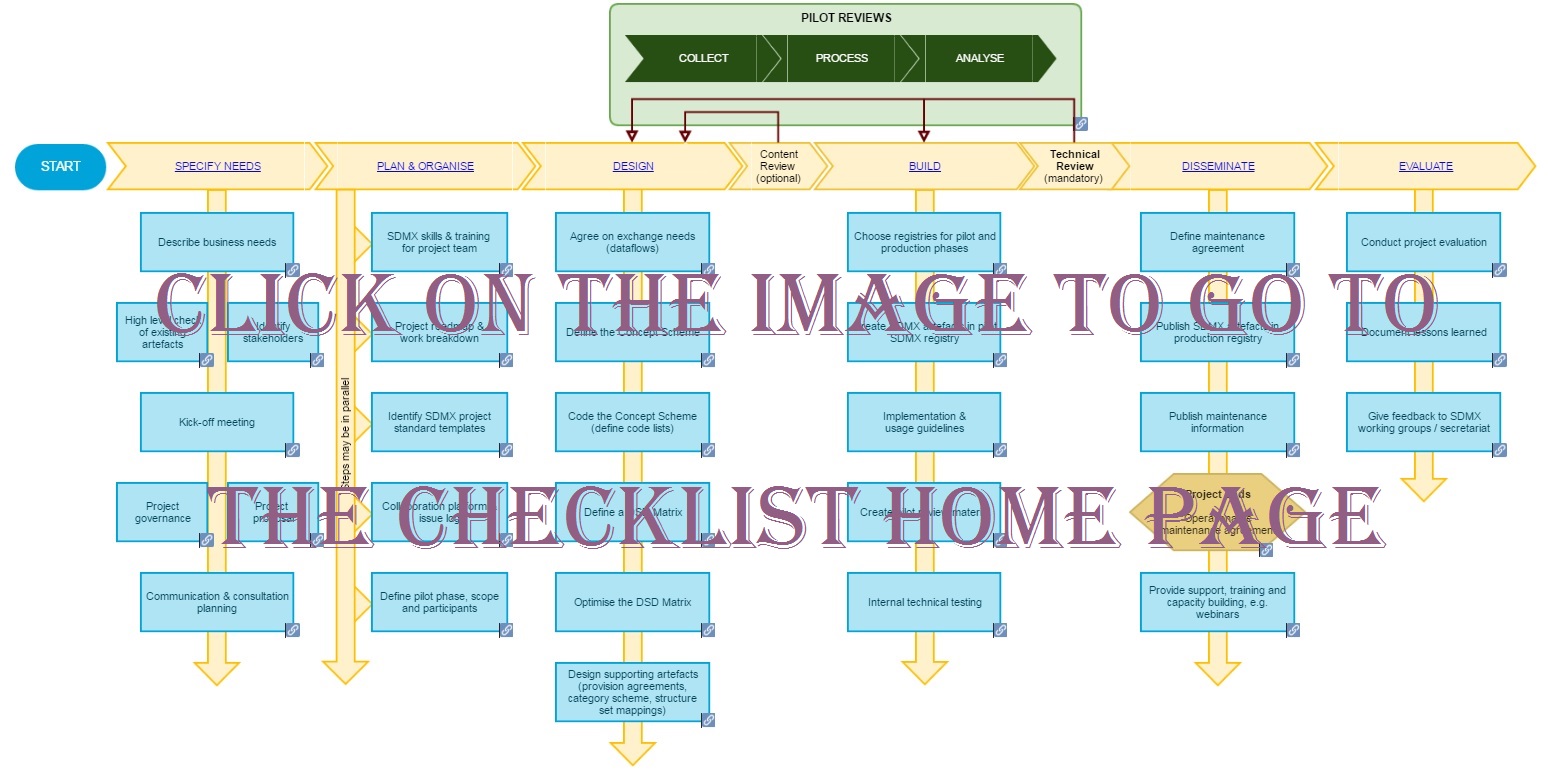
Checklist for SDMx Design Projects
Introduction
This introductory document (February 2016 version) provides a general description of the various components of the SDMx Content-Oriented Guidelines, namely: cross-domain concepts, code lists, subject-matter domains, glossary, and implementation-specific guidelines. This material is made available to users to enhance and make more efficient the exchange of statistical data and metadata using the SDMx standard.
Concepts
Cross-domain concepts in the SDMx framework describe concepts relevant to many, if not all, statistical domains. SDMx recommends using these concepts whenever feasible in SDMx structures and messages to promote the reuse and exchange of statistical information and related metadata between organisations. These cross-domain concepts can be found in the SDMx Glossary below (under attribute “Type: Cross-domain concept”).
Code Lists
Code lists are predefined sets of terms that serve as standardised values for statistical coded concepts. SDMx cross-domain code lists facilitate interoperability by supporting cross-domain concepts. Using common code lists enhances efficiency, simplifies maintenance, and reduces the need for complex mapping systems and interfaces for data and metadata delivery. Consequently, selecting the right code lists significantly impacts the effectiveness of data sharing.
For best practices on designing code lists to improve integration and maximize interoperability, refer to the Guidelines for the Creation and Management of SDMx Code Lists.
Statistical subject-matter domains
A statistical subject-matter domain refers to a statistical activity that has common characteristics with respect to variables, concepts and methodologies for data collection and the whole statistical data compilation process. Examples of statistical domains are price statistics, national accounts, and environment or education statistics. The Classification of Statistical Subject-Matter Domains (January 2009 version) is based on the UN Economic Commission for Europe (UNECE) Classification of International Statistical Activities.
Glossary
The SDMx Glossary Version 2.1 (published in December 2020) contains concepts and related definitions used in structural and reference metadata of international organisations and national data-producing agencies. This new version contains many new concept definitions which are coded so that they can be used as structural metadata in machine-to-machine statistical exchanges. All existing definitions have been reviewed with improvements to add to clarity and example use cases.
The SDMx Glossary recommends a common terminology that should be used in order to facilitate communication and understanding. The overall message of the SDMx Glossary is: if a term is used, then its precise meaning should correspond to the Glossary definition, and any reference to a particular phenomenon described in the Glossary should use the appropriate term.
Users interested in making direct links to specific terms in the Glossary (e.g. for citations, ease of navigation) are invited to use the html version of the Glossary. Let us assume that you want your users to be directly referred to the concept “Content-oriented guidelines (COG)” without them having to search the whole Glossary. Once the Glossary page is open, go through the table of contents until you spot the entry “Content-oriented guidelines (COG)”. You then have two options: a) if you do not want to check the content of the entry (because you already know that it is the concept you are interested in), just do a right-click and select “Copy link address” in Chrome browser, “Copy Link Location” in Netscape, Opera and Firefox browsers, “Copy shortcut” in Internet Explorer browser, or similar functionality in other browsers; b) if you want to check the content of the entry before taking any action, click on the link; you will then be redirected to the place in the document where the entry “Content-oriented guidelines (COG)” is defined; if the entry meets your needs, simply copy the URL displayed in the address bar of your browser and paste it in your document. In the case of the “Content-oriented guidelines (COG)”, the link will be the following: https://sdmx.org/wp-content/uploads/SDMx_Glossary_Version_2_1_December_2020.htm#_Toc59116750 (the segment “#_Toc59116750” is the part of the address that makes the concept directly referenceable).
Please note that the SDMx Glossary is also available as a Cross-Domain Concept Scheme from the SDMx Registry.
Governance of SDMx artefacts
The “Reference Framework for SDMx Structural Metadata Governance” provides guidance to agencies for implementing the most appropriate governance architecture to maintain SDMx Structural Metadata. Thereby, agencies may improve the quality and maintenance of their structural metadata. Through use of this guideline, improvements may be achieved in reporting clarity, reviewing, resource management and structural metadata maintenance. The guideline includes variations on the reference framework to adapt to agencies different needs and resources. Each variation includes comparative indicators to help analyse which one may be the most suitable to implement.
The document “Governance of commonly used SDMx metadata artefacts” (Version 1.3, September 2018) describes in more detail how the principles outlined in the reference framework mentioned above are implemented for artefacts owned and maintained by the SDMx Sponsors or for artefacts used for global data exchange and stored in the Global SDMx Registry.
Other Guidelines
- Guidelines on Using SDMx Annotations
- Standardising Reference Metadata Reporting in SDMx
- Modelling Statistical Domains in SDMx
- Guidelines for Representing Methodological Changes in Data Structure Definitions
- Guidelines for SDMx Data Structure Definitions
- Guidelines for the Creation and Management of SDMx Code Lists
- Guidelines on the Versioning of SDMx Artefacts
- Guidelines on Non-Calendar Year Reporting of Data
- Possible Ways of Implementing the Observation Status Concept
- Guidelines for Confidentiality and Embargo in SDMx
- Guidelines on Coding Time Transformations in SDMx
- Guidelines for SDMx Concept Roles
- Checklist for SDMx Data Providers
- SDMx Global Registry Content Policy
- Guidelines for SDMx Hierarchies
- Guidelines for Modelling Vintages in SDMx
- Guidelines for Modelling Units of Measure in SDMx
Guidelines on using SDMx Annotations (Back to Table of Contents)
The aim of this guideline is to improve machine interactions by proposing a controlled vocabulary for the Type property of the SDMx Annotation construct and a recommended usage for the other properties that will greatly improve the interoperability of Annotations between SDMx-compliant organisations. Version 2.0 adapts the guideline to SDMx 3.0, extends the controlled vocabulary of annotations, and clarifies the text.
Standardising Reference Metadata Reporting in SDMx (Back to Table of Contents)
The goal of this guideline is to increase the efficiency of reference metadata exchange between statistical agencies, and for dissemination (where the consumer may not be known). The quality and timeliness of reference metadata exchange may be improved and harmonised, thereby enabling statistical data to be described more thoroughly in a comparable way using automated, shared systems. This guideline on “Standardising Reference Metadata Reporting in SDMx” (Version 1.0, June 2019) includes a Global Reference Metadata Concept Scheme (MCS) that enumerates a standard list of reference metadata concepts. The Global MCS is not sufficient to implement an exchange; therefore, the document also describes how to derive implementation structures from the Global MCS.By following the guideline, the same tools and mappings may be used across separate metadata flows, agencies and domains using community-driven systems, thus saving on reinvention of the same functionality. Furthermore, the use of the Global MCS is intended to boost the automation of metadata exchange.
Modelling Statistical Domains in SDMx (Back to Table of Contents)
The document “Modelling Statistical Domains in SDMx” (Version 2.0, June 2018) outlines general principles on how to design and create SDMx artefacts in a statistical domain, following a step-by-step approach to design based on the SDMx information model and, complementing the existing guidelines on Data Structure Definitions and Codelists.The document includes how to determine the number of Data Structure Definitions (DSDs) for a subject-matter domain and recommends that a decision on this should come after a discussion on all the parameters of the data collection exercise.
Guidelines for representing methodological changes in Data Structure Definitions (Back to Table of Contents)
The document “Guidelines for representing methodological changes in Data Structure Definitions” (Version 1.0, April 2019) provides recommendations on how to represent methodological changes for several use cases. When designing SDMx artefacts for an implementation project, one major design choice is the dimensionality of the Data Structure Definition(s), that is, which and how many dimensions are used to uniquely identify the relevant time series. Various trade-offs related to this design choice, such as between DSD complexity and parsimony, are discussed in the Modelling Guidelines. One aspect that is mentioned in the Modelling Guidelines, but not elaborated in detail, is the one of structural stability in case of methodological changes. In other words, how future-proof is the DSD? How many and what kind of changes to the DSD are required when certain aspects of the underlying data change and the DSD needs to represent both, pre-change and post-change data, in different time series? If certain future changes are already expected when the DSD is originally designed, dimensions (or attributes) covering these changes will be included in the DSD. If the DSD was designed without expecting changes, additional dimensions or attributes will have to be introduced at a later stage.
Guidelines for SDMx Data Structure Definitions (Back to Table of Contents)
The development of SDMx Data Structure Definitions in many statistical domains raised the need for guidance on the design of DSDs. The SDMx initiative now releases such guidelines based on conceptual considerations and first hand experiences with the development of DSDs. The document “Guidelines for SDMx Data Structure Definitions” (Version 1.0, June 2013) outlines general design principles for DSDs such as reuse of existing concepts and code lists, and principles such as keeping the DSDs simple. The guidelines describe the different uses of DSDs, based on different user needs. And discuss the advantages and disadvantages of data structures in different domains. They provide context-specific recommendations instead of prescribing “the best” one-size-fits-all approach. For DSD designers, a step-by-step guide for designing DSDs is also included.
Guidelines for the Creation and Management of SDMx Code Lists (Back to Table of Contents)
The “Guidelines for the creation and Management of SDMx Code Lists” provide best practices for developing code lists, particularly in SDMx implementations across statistical domains. Their use is strongly recommended when designing and implementing SDMx-compliant Data Structure Definitions (DSDs).
Version 4.0 (February 25, 2025) includes features from SDMx 3.0, along with new and updated recommendations.
Guidelines on the Versioning of SDMx Artefacts (Back to Table of Contents)
The “Guidelines on the Versioning of SDMx Artefacts” (Version 1.0, November 2015) provide recommendations on how to version SDMx artefacts inspired by “semantic versioning”, i.e. a formal convention for specifying compatibility between the different versions of a “versionable” artefact (a SDMx artefact that has an associated version number). Versioning is central to SDMx because it guarantees the stability of references to SDMx artefacts. This is of the utmost importance given the sometimes strong dependencies between artefacts, especially in Data Structure Definitions (DSDs). The document contains three main recommendations: a) numbering system and syntax; b) types of artefact changes and their versioning impact; c) how versioning works for inter-dependent artefacts. The document’s appendix contains examples of several types of changes and their versioning impact.
Guidelines on Non-Calendar Year Reporting of Data (Back to Table of Contents)
In many cases, data that are exchanged in SDMx data messages do not relate to the calendar year. However, many statistical system implementations require that data are mapped to and stored as the real calendar. The document “Guidelines on Non-Calendar Year Reporting of Data” (Version 1.0, November 2016) provides recommendations for four use cases of such non-calendar year data: a) Reporting year is equal to the calendar year; b) Reporting year starts on the first day of a month different to January; c) Reporting year starts on a given day in the year, and d) Reporting year ends on a given day in the year.
Possible Ways of Implementing the Observation Status Concept (Back to Table of Contents)
The “Observation status” code list has a heterogeneous character as it mixes concepts which are not always mutually exclusive (e.g. a missing value can generate a break in time series). This means that several flags can be allocated to one statistical observation. The document “Possible Ways of Implementing the Observation Status Concept” (Version 2.0, May 2019) describes the possible options for doing that, including the recommended solution, and explains their advantages and disadvantages.
Guidelines for Confidentiality and Embargo in SDMx (Back to Table of Contents)
The “Guidelines for Confidentiality and Embargo in SDMx” (Version 2.0, 19 January 2018) cover the confidentiality aspects in SDMx data exchange, including embargo scenarios. The aim is to provide a consistent and practical way to represent these aspects in SDMx artefacts in order to promote cross-domain consistency and harmonise methodology and processes. The paper presents the use case scenarios related to confidentiality and embargo. Based on the use cases, recommendations are provided on how to represent both elements in the SDMx model.
Guidelines on coding time transformations in SDMx(Back to Table of Contents)
The “Guidelines on coding time transformations in SDMx” (Version 1.0, September 2016) describe two methods that may be used to code a time transformation, defined as a time-related operation performed on a time series, solely involving observations of that time series. Examples of such time transformations are growth rates, cumulative sums over several periods and moving averages. Both of the methods described in the guideline are included as separate use cases. The aim of this document is to demonstrate that guidance and a standard approach is available and promoted for each use case.
Guidelines for SDMx Concept Roles(Back to Table of Contents)
The document “Guidelines for SDMx Concept Roles” (Version 1.1, May 2022) describes SDMx Concept Roles and their use. It also proposes a cross-domain Concept scheme that defines the set of concept roles for SDMx 2.1, which also applies to SDMx 3.0, and gives examples on concept role implementation in both SDMx 2.0 and SDMx 2.1. A concept role gives a particular context to a concept for easy and systematic interpretation by machine processing and visualization tools. For example, the concepts REPORTING_AREA and COUNTERPART_AREA are different concepts but they are both geographical characteristics, therefore they can be associated with the same concept role ID: “GEO”. This allows visualization systems to interpret these concepts as geographical data in order to generate maps. The implementation of concept roles is different in versions 2.0 and 2.1 of the SDMx technical standard. Examples for both versions are included in the appendix. The Concept Roles are available as an SDMx Concept Scheme from the SDMx Global Registry.
Checklist for SDMx Data Providers(Back to Table of Contents)
The aim of the Checklist for SDMx Data Providers is to help statistical agencies implement the provision of SDMx data based on existing structures, such as Global DSDs. A prerequisite before starting SDMx implementation is to define and store SDMx structural metadata artefacts in a shared location (such as the SDMx Global Registry). For guidance and how to define SDMx artefacts, please refer to the Checklist for SDMx Design Projects.
Examples for using the checklist may be reporting data to international organisations (e.g. reporting of ESA 2010 to Eurostat), dissemination of national data using SDMx, or for international agreements (e.g. SDDS+ adherence in cooperation with IMF). It may be used by project managers to speed up implementations based on best practices. The checklist describes the various activities (the individual boxes) to be achieved, which are organised in process phases (the vertical pillars). The process phases are based on the UNECE Generic Statistical Business Process Model.
Each activity can be clicked through to view its details. Not all activities are compulsory: it depends on the statistical agencies starting point, such as on the level of technology available, and the statistical and SDMx knowledge. Furthermore, the order of activities do not require a sequential/waterfall implementation, and there will naturally be some feedback loops; for example, after the Test phase it could be necessary to return to the Design or Planning phases.
The checklist should be usable with most project management methodologies such as Waterfall, KANBAN, Scrum, etc.
The document “checklist for data provider story.docx” contains a story on how to the checklist may be implemented.
SDMx Global Registry Content Policy (Back to Table of Contents)
The document “SDMx Global Registry Content Policy” (Version 1.0, March 2015) proposes a policy for artefacts stored, maintained and disseminated from the SDMx global registry (GR). Defining precisely which artefacts should go into the GR and which ones should not is crucial as the GR will play a central role in providing SDMx implementers with final, reliable, up-to-date, harmonised and validated SDMx artefacts.
Guidelines for SDMx Hierarchies (Back to Table of Contents)
The “Guidelines for SDMx Hierarchies” (Version 1.0, September 2025) illustrates the use case for hierarchies in SDMx, provide examples and recommend best practices for its implementation. Hierarchies are commonly used to represent various relationships among elements in the code list and classifications. They play a crucial role in data management systems for tasks such as data modelling and data dissemination.
Guidelines for modelling Vintages in SDMx (Back to Table of Contents)
The “Guidelines for modelling Vintages in SDMx” (Version 1.0, October 2025) provides recommendations on how to work with vintages for several use cases and present practical examples for its implementation. Vintage data allows academics to reproduce others’ research, build more accurate forecasting models, and analyse economic policy decisions using the data available at the time.
Guidelines for Modelling Units of Measure in SDMx (Back to Table of Contents)
The role of units of measure in statistical data modelling is critical for ensuring consistency, accuracy, and interpretability. Measurement units provide a standardized way to quantify data, enabling immediate assessment of comparability and defining the scope for computations.
Accurate and consistent unit conversions are essential for maintaining data integrity and enabling meaningful analysis when comparing statistical indicators. This underscores the importance of “Guidelines for Modelling Units of Measure in SDMx” (Version 1.0, November 2025). These guidelines establish a framework for organising and standardising how units of measure are represented and managed within SDMx data models. They are designed for statistical data modelers working with multidimensional data, primarily in SDMx, but they also extend to data-warehousing applications in general. The patterns proposed are rooted in well-established international standards in science and engineering.
This webpage is maintained by the SDMx Statistical Working Group (SWG), comprised of members coming from national and international banking and statistical organisations. The SWG uses Github for the maintenance and development of the SDMx Statistical Guidelines. For more information, see the SWG page on Github at https://github.com/sdmx-swg.
LICENSE
The SDMx content-oriented guidelines and their documentation are subject to the CC BY-SA 4.0 (Attribution-Share-Alike) license. You are free to:
- Share— copy and redistribute the material in any medium or format
- Adapt— remix, transform, and build upon the material for any purpose, even commercially.
These are the terms of the license:
- Attribution— You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- ShareAlike— If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
- No additional restrictions— You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
The full license text is here.
- For enquiries about the SDMx Statistical Guidelines: swg@sdmx.org
- To connect with SDMx users and experts: SDMx User Forum